Motivation
为什么我们在 Spark 中需要 node decommission 这个特性?SPARK-20624 详细阐述了我们需要它的理由
同时这个方案也是为了对 Yarn 的弹性混部的 Spark 进行稳定性优化,提供一些思路。
这其中最重要的点,就是 executor shutdown, 将会导致需要对 shuffle 和 cache 数据的重算。Node decommission 这个特性,使得我们可以将 block 和 shuffle 数据迁移到其他 executor 上,降低 shutdown 对任务的影响。
以下将会从 decommission 的 metadata(将 executor 在 driver 侧标记,并触发 decommission) 和 data migration(触发后,完成 rdd 和 shuffle block 的迁移) 两部分来解读
Decommission trigger (metadata)
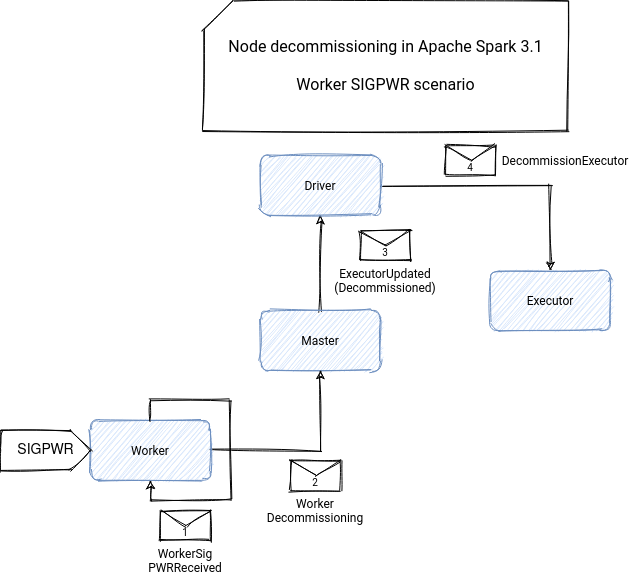
一旦 driver 收到 node decommission 的消息,就会将此 node 下的 executor 都通知为进入 decommissioning 状态,并将其从 scheduler 侧 exclude, 避免 task 被 assign 过去。
同时,executor 在被标记为 decommission 后,就会进行上述的 data migration 流程(如果参数开启的话)
Data migration
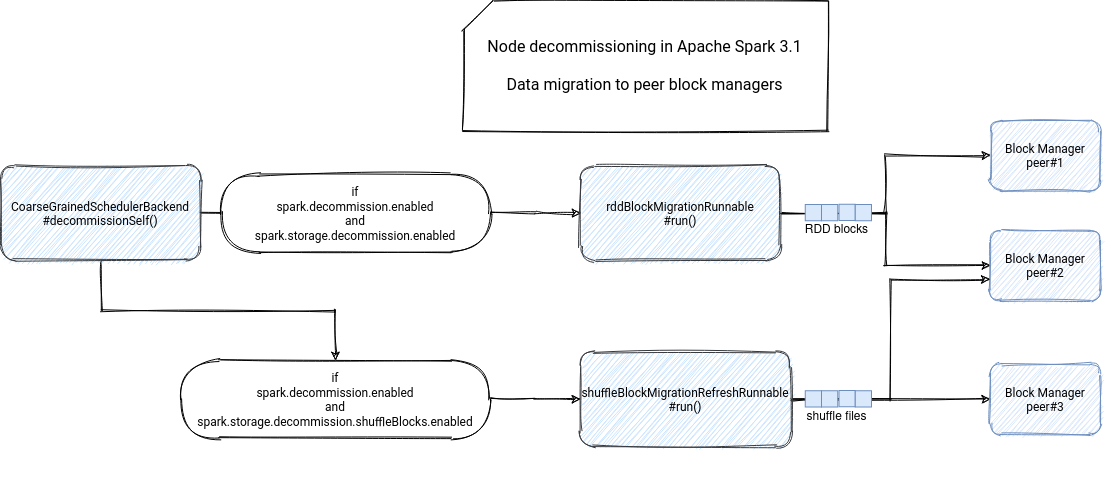
# 参数控制了是否允许进行 executor decommission
spark.decommission.enabled
# 参数控制了是否要进行 data migration
spark.storage.decommission.enabled
# 参数控制了是否要对 shuffle block 进行 migration
spark.storage.decommission.shuffleBlocks.enabled
# 控制 rdd block 迁移
spark.storage.decommission.rddBlocks.enabled
代码分析 - Driver
// 代码路径: core/src/main/scala/org/apache/spark/scheduler/cluster/CoarseGrainedSchedulerBackend.scala
/**
* Request that the cluster manager decommission the specified executors.
*
* @param executorsAndDecomInfo Identifiers of executors & decommission info.
* @param adjustTargetNumExecutors whether the target number of executors will be adjusted down
* after these executors have been decommissioned.
* @param triggeredByExecutor whether the decommission is triggered at executor.
* @return the ids of the executors acknowledged by the cluster manager to be removed.
*/
override def decommissionExecutors(
executorsAndDecomInfo: Array[(String, ExecutorDecommissionInfo)],
adjustTargetNumExecutors: Boolean,
triggeredByExecutor: Boolean): Seq[String] = withLock {
// Do not change this code without running the K8s integration suites
val executorsToDecommission = executorsAndDecomInfo.flatMap { case (executorId, decomInfo) =>
// Only bother decommissioning executors which are alive.
if (isExecutorActive(executorId)) {
scheduler.executorDecommission(executorId, decomInfo)
executorsPendingDecommission(executorId) = decomInfo.workerHost
Some(executorId)
} else {
None
}
}
logInfo(s"Decommission executors: ${executorsToDecommission.mkString(", ")}")
// If we don't want to replace the executors we are decommissioning
if (adjustTargetNumExecutors) {
adjustExecutors(executorsToDecommission)
}
// Mark those corresponding BlockManagers as decommissioned first before we sending
// decommission notification to executors. So, it's less likely to lead to the race
// condition where `getPeer` request from the decommissioned executor comes first
// before the BlockManagers are marked as decommissioned.
// Note that marking BlockManager as decommissioned doesn't need depend on
// `spark.storage.decommission.enabled`. Because it's meaningless to save more blocks
// for the BlockManager since the executor will be shutdown soon.
scheduler.sc.env.blockManager.master.decommissionBlockManagers(executorsToDecommission)
if (!triggeredByExecutor) {
executorsToDecommission.foreach { executorId =>
logInfo(s"Notify executor $executorId to decommissioning.")
executorDataMap(executorId).executorEndpoint.send(DecommissionExecutor)
}
}
conf.get(EXECUTOR_DECOMMISSION_FORCE_KILL_TIMEOUT).map { cleanupInterval =>
val cleanupTask = new Runnable() {
override def run(): Unit = Utils.tryLogNonFatalError {
val stragglers = CoarseGrainedSchedulerBackend.this.synchronized {
executorsToDecommission.filter(executorsPendingDecommission.contains)
}
if (stragglers.nonEmpty) {
logInfo(s"${stragglers.toList} failed to decommission in ${cleanupInterval}, killing.")
killExecutors(stragglers, false, false, true)
}
}
}
cleanupService.map(_.schedule(cleanupTask, cleanupInterval, TimeUnit.SECONDS))
}
executorsToDecommission
}代码分析-Executor decommission
// 代码路径:core/src/main/scala/org/apache/spark/executor/CoarseGrainedExecutorBackend.scala
private def decommissionSelf(): Unit = {
if (!env.conf.get(DECOMMISSION_ENABLED)) {
logWarning(s"Receive decommission request, but decommission feature is disabled.")
return
} else if (decommissioned) {
logWarning(s"Executor $executorId already started decommissioning.")
return
}
val msg = s"Decommission executor $executorId."
logInfo(msg)
try {
decommissioned = true
val migrationEnabled = env.conf.get(STORAGE_DECOMMISSION_ENABLED) &&
(env.conf.get(STORAGE_DECOMMISSION_RDD_BLOCKS_ENABLED) ||
env.conf.get(STORAGE_DECOMMISSION_SHUFFLE_BLOCKS_ENABLED))
if (migrationEnabled) {
env.blockManager.decommissionBlockManager()
} else if (env.conf.get(STORAGE_DECOMMISSION_ENABLED)) {
logError(s"Storage decommissioning attempted but neither " +
s"${STORAGE_DECOMMISSION_SHUFFLE_BLOCKS_ENABLED.key} or " +
s"${STORAGE_DECOMMISSION_RDD_BLOCKS_ENABLED.key} is enabled ")
}
if (executor != null) {
executor.decommission()
}
// Shutdown the executor once all tasks are gone & any configured migrations completed.
// Detecting migrations completion doesn't need to be perfect and we want to minimize the
// overhead for executors that are not in decommissioning state as overall that will be
// more of the executors. For example, this will not catch a block which is already in
// the process of being put from a remote executor before migration starts. This trade-off
// is viewed as acceptable to minimize introduction of any new locking structures in critical
// code paths.
val shutdownThread = new Thread("wait-for-blocks-to-migrate") {
override def run(): Unit = {
var lastTaskRunningTime = System.nanoTime()
val sleep_time = 1000 // 1s
// This config is internal and only used by unit tests to force an executor
// to hang around for longer when decommissioned.
val initialSleepMillis = env.conf.getInt(
"spark.test.executor.decommission.initial.sleep.millis", sleep_time)
if (initialSleepMillis > 0) {
Thread.sleep(initialSleepMillis)
}
while (true) {
logInfo("Checking to see if we can shutdown.")
if (executor == null || executor.numRunningTasks == 0) {
if (migrationEnabled) {
logInfo("No running tasks, checking migrations")
val (migrationTime, allBlocksMigrated) = env.blockManager.lastMigrationInfo()
// We can only trust allBlocksMigrated boolean value if there were no tasks running
// since the start of computing it.
if (allBlocksMigrated && (migrationTime > lastTaskRunningTime)) {
logInfo("No running tasks, all blocks migrated, stopping.")
exitExecutor(0, ExecutorLossMessage.decommissionFinished, notifyDriver = true)
} else {
logInfo("All blocks not yet migrated.")
}
} else {
logInfo("No running tasks, no block migration configured, stopping.")
exitExecutor(0, ExecutorLossMessage.decommissionFinished, notifyDriver = true)
}
} else {
logInfo(s"Blocked from shutdown by ${executor.numRunningTasks} running tasks")
// If there is a running task it could store blocks, so make sure we wait for a
// migration loop to complete after the last task is done.
// Note: this is only advanced if there is a running task, if there
// is no running task but the blocks are not done migrating this does not
// move forward.
lastTaskRunningTime = System.nanoTime()
}
Thread.sleep(sleep_time)
}
}
}
shutdownThread.setDaemon(true)
shutdownThread.start()
logInfo("Will exit when finished decommissioning")
} catch {
case e: Exception =>
decommissioned = false
logError("Unexpected error while decommissioning self", e)
}
}
}
问题:
此处针对的是 executor 上的data, 如果是开启了 external shuffle service, 则是否会进行 migration 呢?
深入分析
对于上述的 decommission trigger 我们暂时先只讨论 yarn 下的模式。在通过 apache/spark#35683 可以让 Spark 感知到 Yarn 的 NodeManager 进入到了 decommission 状态,从而触发 Spark 引擎内部对 node decomission 的触发流程(这边是存在双层调度,Yarn 的资源调度,Spark 的应用层task 调度)。
问题:
但是上述的 patch 目前是在禁用了 external shuffle service 情况下才生效的,这是何故?
从 PR 的 comment 来看,是因为认为 yarn node decommission 并不意味着,ESS 上的数据需要被迁移。另外还有一点就是 push based shuffle service,需要更多的适配,因为 push -> reducer 时,也需要 check reducer 是否是被标记退役的节点
对于前者,我觉得此处需要考虑两种情况,ESS 是否和需要 decommission 的 host 绑定。
-
绑定:意味着数据需要迁移,因为 node shutdown, ess 上数据也会丢失
-
不绑定:例如 remote shuffle service.
单就上述情况来看,SPARK 也不应该直接根据 ESS 开启情况与否,来决定是否触发 decommission. 而是应该加入另外的参数,来表明是否 ESS 与 host 绑定
从 Design DOC 设计来看, 是考虑过这一点的。
Part 8 (Optional): When there is a node-local external shuffle service
Block migration is only done when an external shuffle service is NOT used OR an entire host is being lost. We'll extend the DecommissionSelf & DecommissionExecutor messages to have a nodeLoss field for situations where an entire host will be lost.
An external shuffle service can either be local to the node or truly off-node (remote). If it is local to the node, then chances are that it is also removed when the node is decommissioned. For example, when YARN and the Standalone scheduler decommission a node, then the external shuffle service on that node would also be removed.
Ideally, we should also implement block migration with an external shuffle service. But a short term fix might be to eagerly clear the shuffle state on decommissioning an executor. (As is done today when a worker is removed by the standalone scheduler). This may save the running job from suffering too many fetch failures/timeouts but it would cost costly re-computation. This approach of forgetting the shuffle state has some overlap with Part 7 above.
另外为了应对目前 ESS 不支持 block migration 的情况下,shuffle service 会面临 fetch failed exception 不断重试的情况,apache/spark#29014 缓解了这个问题。用以解决 shuffle service 在 node 被 decomissioned 之后,shuffle read 只重试一次,加快重算的流程。
此 patch 很有意义,因为 NM pod 中的 executor 和 ess 是不同生命周期的。举个例子,executor 被标记为 decommissioned 之后,上面的任务执行完,即退役。而 ESS 则是同 nm 同周期,生命周期 >= executor.
因此如果直接根据 executor decommissioned 情况,来禁用掉此 executor 的 host 上 ESS, 则对造成很多无用的重算浪费
内部的实践
场景
- 集群内部有的任务开启了 shuffle service,有的没有。yarn 上的 NM 会存在周期性的 decommission,需要保证 Spark 任务的稳定性,特别是在弹性 yarn NM节点数量较多时
- 内部使用 Spark 3.1.1 版本
初步实践
应用patch
- [SPARK-34104][SPARK-34105][CORE][K8S] Maximum decommissioning time & allow decommissioning for excludes
- [SPARK-30835][SPARK-39018][CORE][YARN] Add support for YARN decommissioning when ESS is disabled #35683
改造
在 ESS 开启时,仍然允许进行 yarn executor 的 decommission 操作
参数
设置 spark.decommission.enabled=true
应用上述功能后,可供观测的点
- Driver 侧日志,输出
Decommission executors:xxxx,并据此找到相应的 host, 观察是否在这时间点后被 assign task 了
- 在 NM pod 被关闭后,观察 Spark 任务在 fetch 已经下线节点的 shuffle data 的时候,是不是只重试了一次?还是直接就重算?
Roadmap
下一阶段引入 Remote Shuffle Service
Reference
- https://issues.apache.org/jira/browse/SPARK-20624
- https://www.waitingforcode.com/apache-spark/what-new-apache-spark-3.1-nodes-decommissioning/read
- https://aws.amazon.com/cn/blogs/big-data/spark-enhancements-for-elasticity-and-resiliency-on-amazon-emr/
Motivation
为什么我们在 Spark 中需要 node decommission 这个特性?SPARK-20624 详细阐述了我们需要它的理由
在云上环境,如果你使用了 spot instances 实例,那么这就意味着 instances 不是稳定的,随时可能被抢占或关停,这就导致你不得不重算在 instance 上的数据
在一个共享集群中,因有些 job 有着更高的优先级,就会抢占低优先级任务
同时这个方案也是为了对 Yarn 的弹性混部的 Spark 进行稳定性优化,提供一些思路。
这其中最重要的点,就是 executor shutdown, 将会导致需要对 shuffle 和 cache 数据的重算。Node decommission 这个特性,使得我们可以将 block 和 shuffle 数据迁移到其他 executor 上,降低 shutdown 对任务的影响。
以下将会从 decommission 的 metadata(将 executor 在 driver 侧标记,并触发 decommission) 和 data migration(触发后,完成 rdd 和 shuffle block 的迁移) 两部分来解读
Decommission trigger (metadata)
一旦 driver 收到 node decommission 的消息,就会将此 node 下的 executor 都通知为进入 decommissioning 状态,并将其从 scheduler 侧 exclude, 避免 task 被 assign 过去。
同时,executor 在被标记为 decommission 后,就会进行上述的 data migration 流程(如果参数开启的话)
Data migration
代码分析 - Driver
代码分析-Executor decommission
深入分析
对于上述的 decommission trigger 我们暂时先只讨论 yarn 下的模式。在通过 apache/spark#35683 可以让 Spark 感知到 Yarn 的 NodeManager 进入到了 decommission 状态,从而触发 Spark 引擎内部对 node decomission 的触发流程(这边是存在双层调度,Yarn 的资源调度,Spark 的应用层task 调度)。
从 PR 的 comment 来看,是因为认为 yarn node decommission 并不意味着,ESS 上的数据需要被迁移。另外还有一点就是 push based shuffle service,需要更多的适配,因为 push -> reducer 时,也需要 check reducer 是否是被标记退役的节点
对于前者,我觉得此处需要考虑两种情况,ESS 是否和需要 decommission 的 host 绑定。
绑定:意味着数据需要迁移,因为 node shutdown, ess 上数据也会丢失
不绑定:例如 remote shuffle service.
单就上述情况来看,SPARK 也不应该直接根据 ESS 开启情况与否,来决定是否触发 decommission. 而是应该加入另外的参数,来表明是否 ESS 与 host 绑定
从 Design DOC 设计来看, 是考虑过这一点的。
另外为了应对目前 ESS 不支持 block migration 的情况下,shuffle service 会面临 fetch failed exception 不断重试的情况,apache/spark#29014 缓解了这个问题。用以解决 shuffle service 在 node 被 decomissioned 之后,shuffle read 只重试一次,加快重算的流程。
此 patch 很有意义,因为 NM pod 中的 executor 和 ess 是不同生命周期的。举个例子,executor 被标记为 decommissioned 之后,上面的任务执行完,即退役。而 ESS 则是同 nm 同周期,生命周期 >= executor.
因此如果直接根据 executor decommissioned 情况,来禁用掉此 executor 的 host 上 ESS, 则对造成很多无用的重算浪费
内部的实践
场景
初步实践
应用patch
改造
在 ESS 开启时,仍然允许进行 yarn executor 的 decommission 操作
参数
设置
spark.decommission.enabled=true应用上述功能后,可供观测的点
Decommission executors:xxxx,并据此找到相应的 host, 观察是否在这时间点后被 assign task 了Roadmap
下一阶段引入 Remote Shuffle Service
Reference